And what if two musical versions don't share melody, harmony, rhythm, or lyrics ?
Welcome to the companion web site of our paper “And what if two musical versions don’t share melody, harmony, rhythm, or lyrics ?”
Train and test datasets
Coming soon…
Audio examples
In this section we provide some illustrative and contrastive examples between Ly, Rh and Me+Ha combination. We display the examples from the article with the YouTube links and some others. Last access to videos : 14/8/2022.
1. Ly-Me+Ha examples
1.1 Ly > Me+Ha
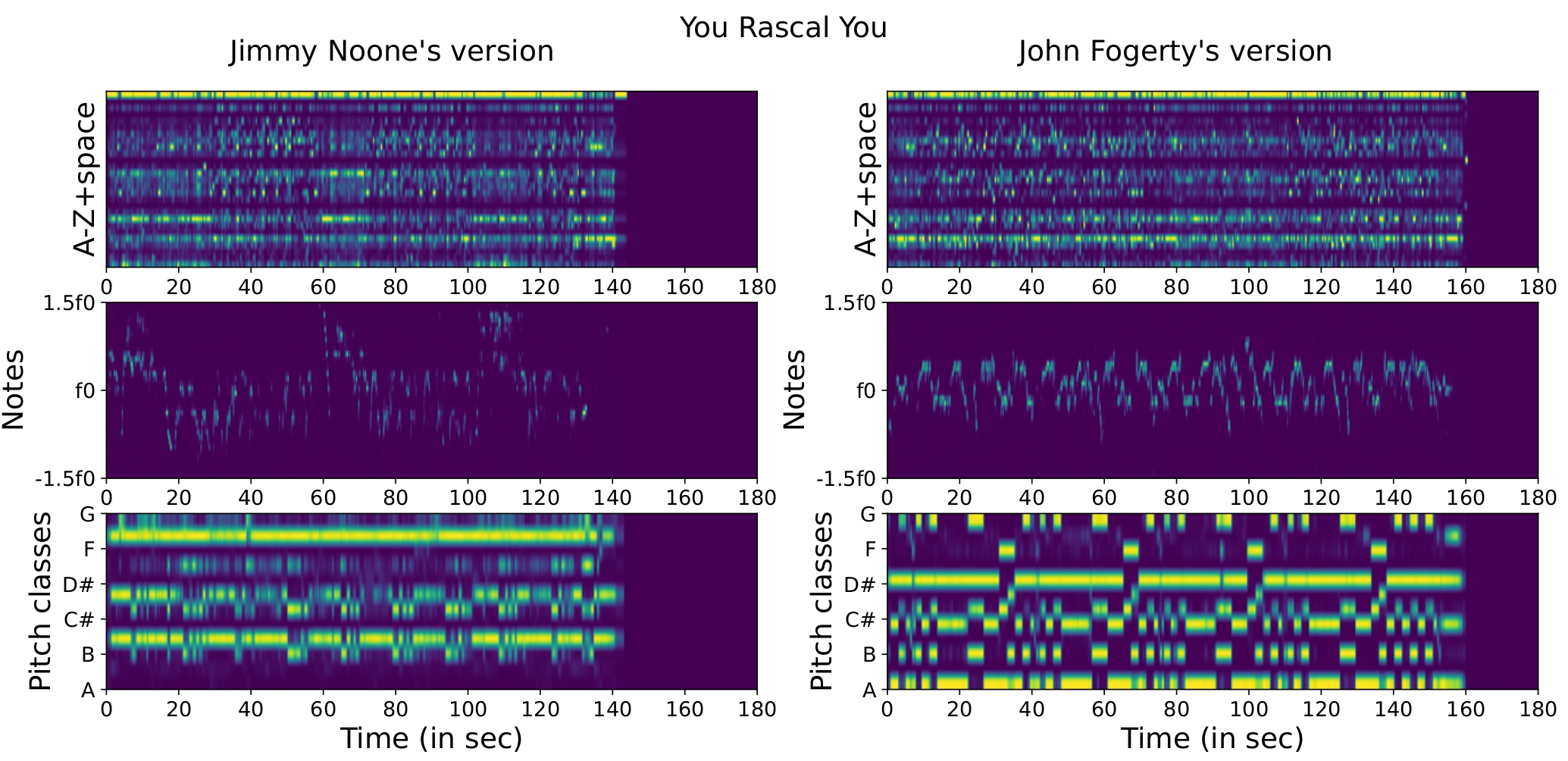
There are many versions whose musical style, melody and harmony differ greatly from the original, and where only the lyrics can still help to identify them. This is illustrated on Figure 1.1.1, which shows that the Jimmy Noone’s and John Fogerty’s versions of “You Rascal You” are very different musically while the lyrics exhibit enough similarity to be correctly identified.
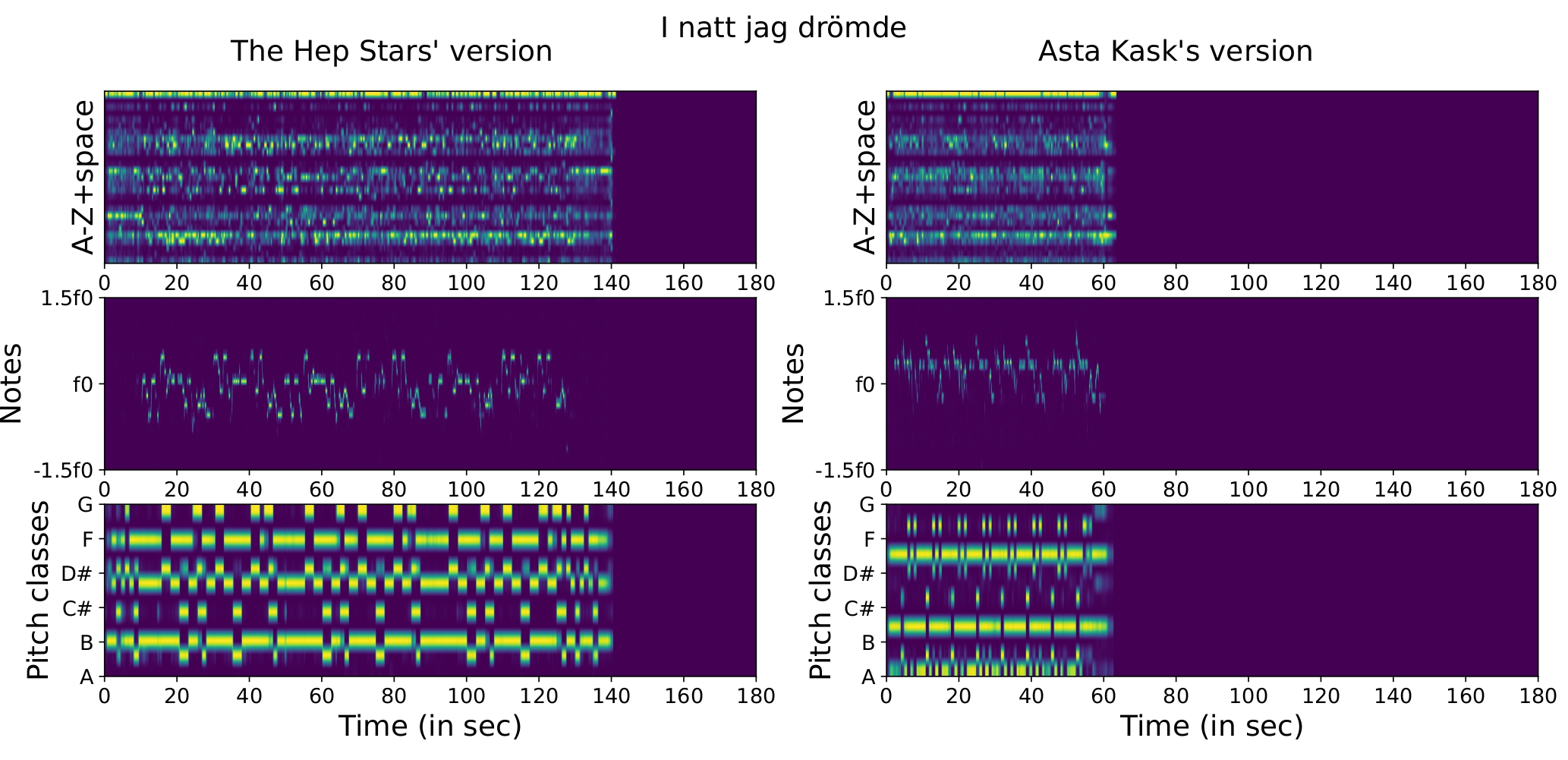
It also appears that our approximated ALR system is efficient for different languages. For instance, the versions of Asta Kask and of The Hep Stars of the song “I natt jag drömde”, are different in melody and harmony while the lyrics remain similar, despite the fact that the lyrics are in Swedish.
1.2 Ly < Me+Ha
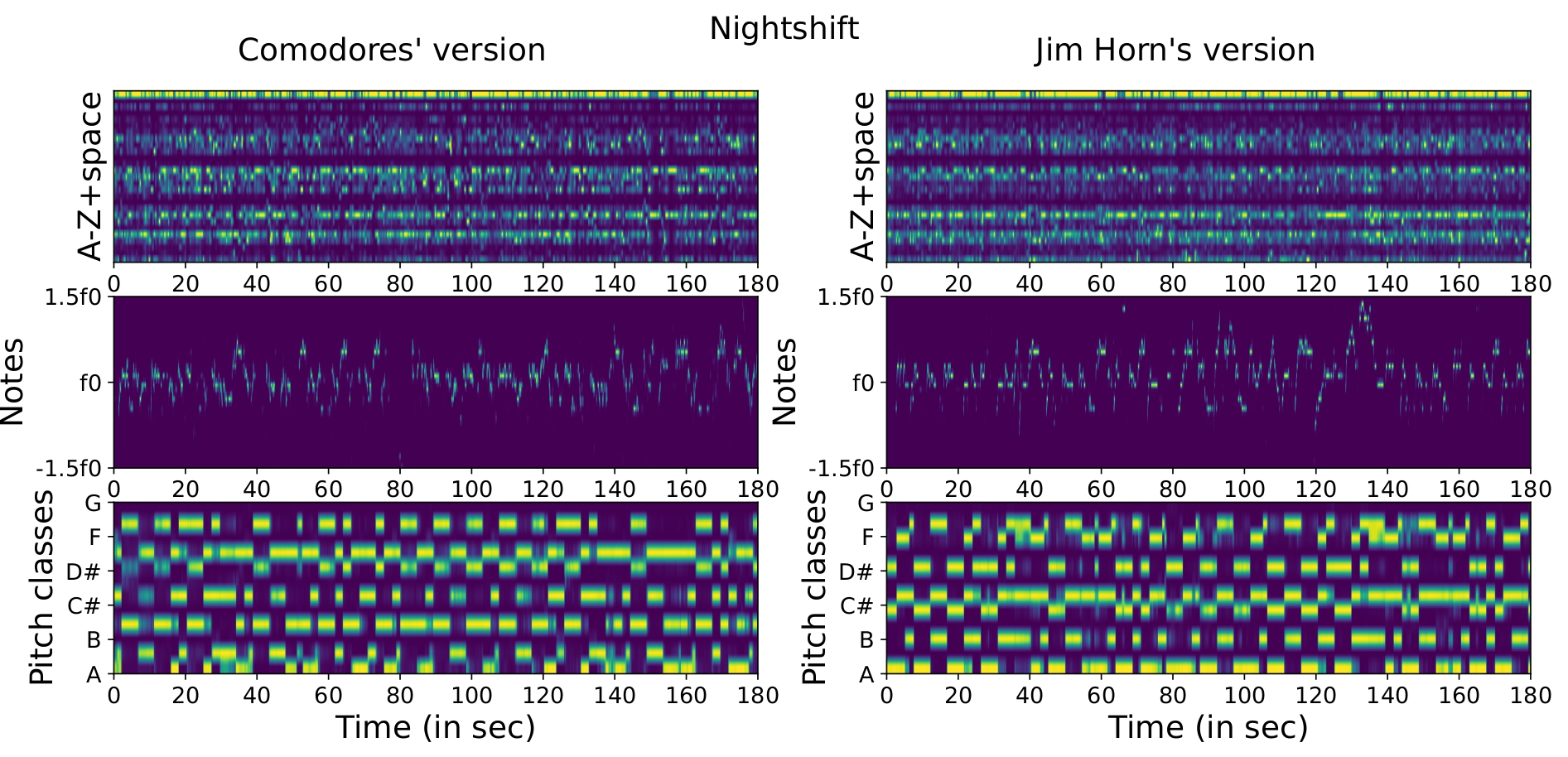
A case were lyrics can be counter-productive is the instrumental version case. In the example shown in Figure 1.2.1, the version of “Nightshift” by the Commodores has lyrics while the one of Jim Horn’s does not. We noticed that the system sometimes considers lead instruments as voices. However, this Ly false negative is correctly caught by the Me+Ha.
2. Rh-Me+Ha examples
2.1 Rh > Me+Ha
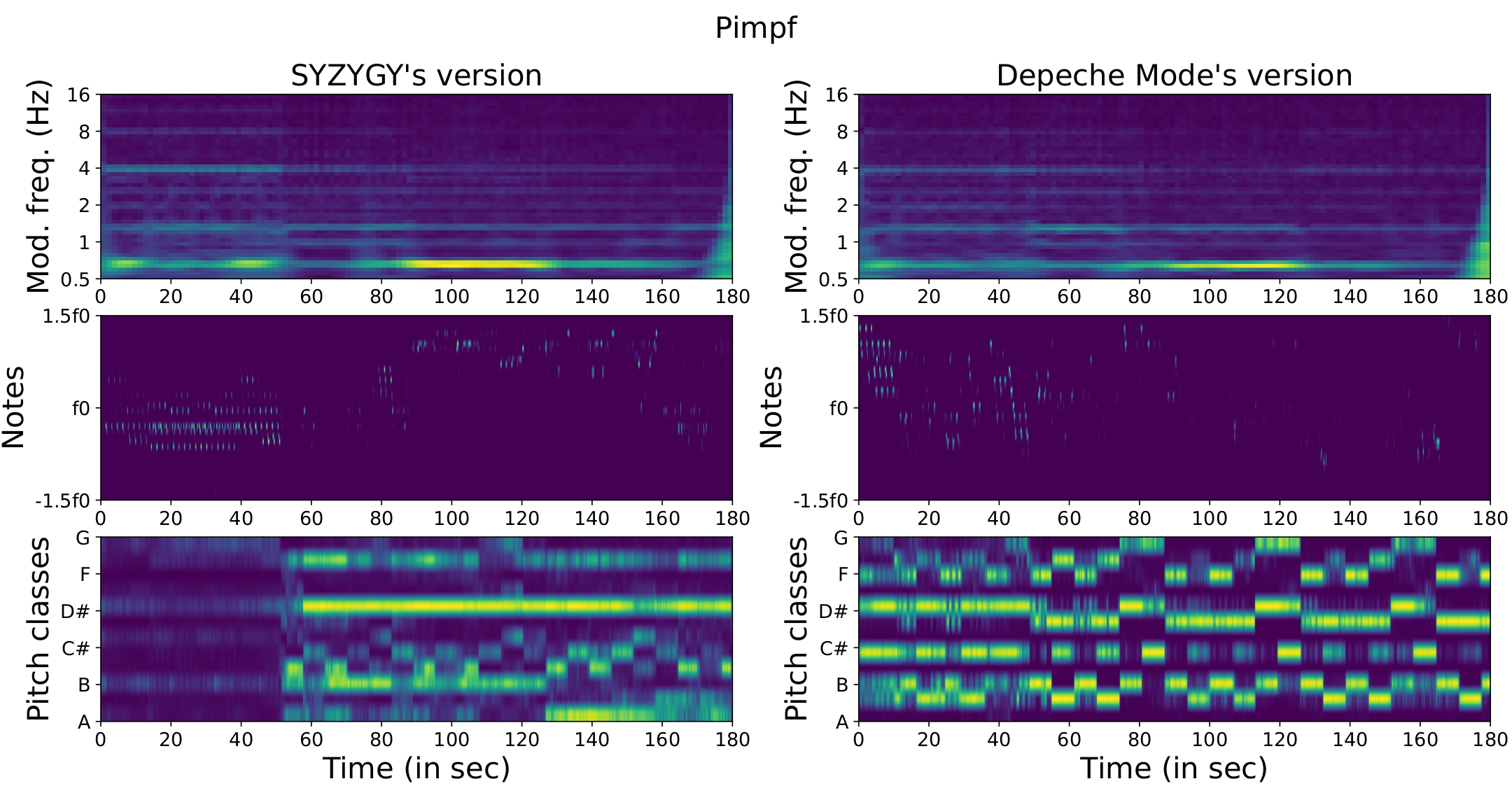
Even though Rh yields poor performances in general, there are cases where it is the only feature available to identify versions. This is illustrated on Figure 1.1.1, which shows the Rh, Me and Ha features for two versions of “Pimpf”. In this song, the melody is almost non-existent, and the harmony is very different between both versions. Only a few bass notes in the middle are salient enough to identify the song, and this short bassline appears similarly on the two FP features.
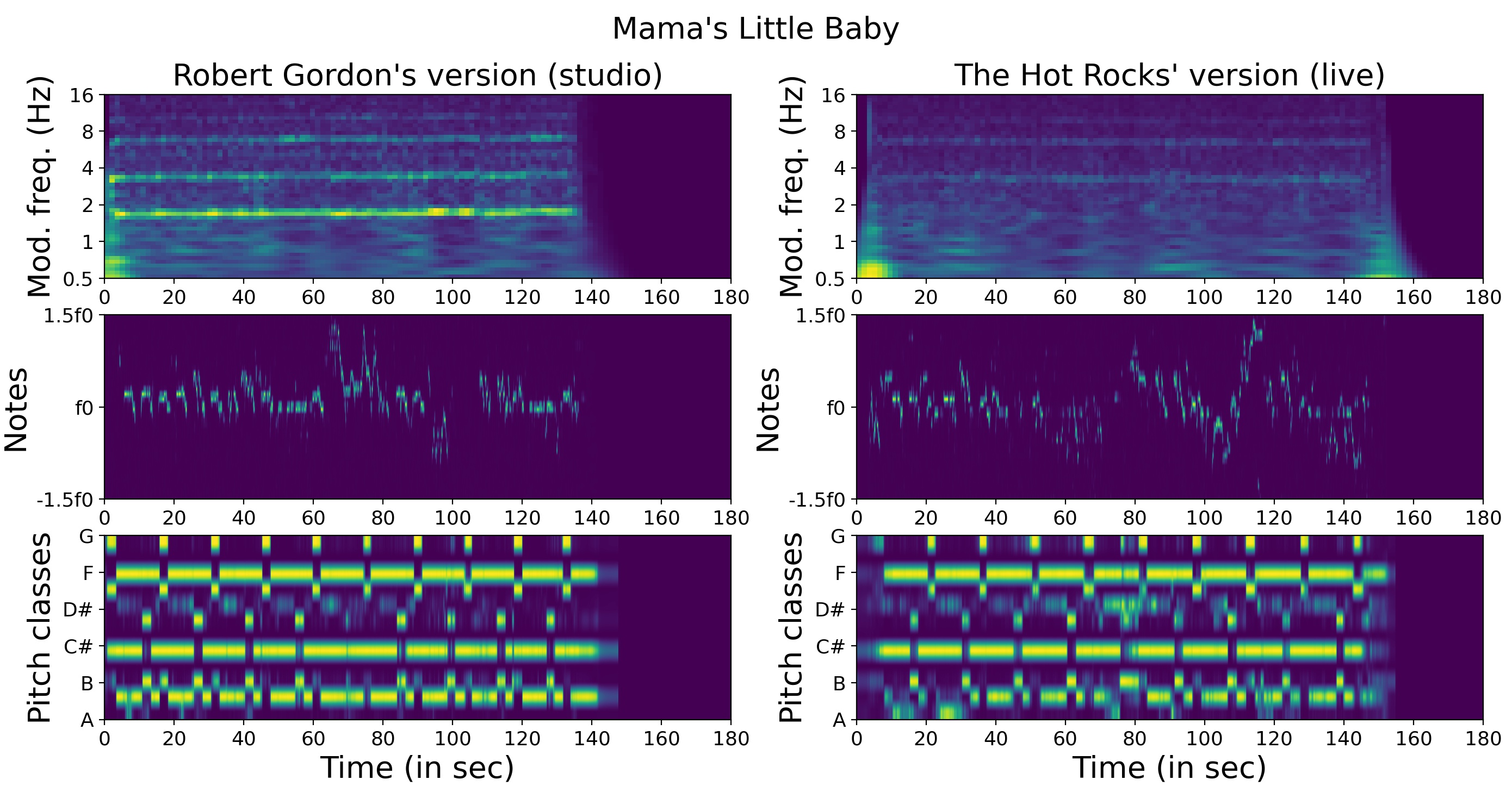
There are also other cases where Rh might be a good discriminating feature, for instance during live concerts. One version of “Mama’s Little Baby” is recorded in studio while the other is a concert filmed from the audience. The Me+Ha distance between these two versions is high because of the bad live recording quality. On the other hand, the drums are distinguishable enough to establish similarity.
2.2 Rh < Me+Ha
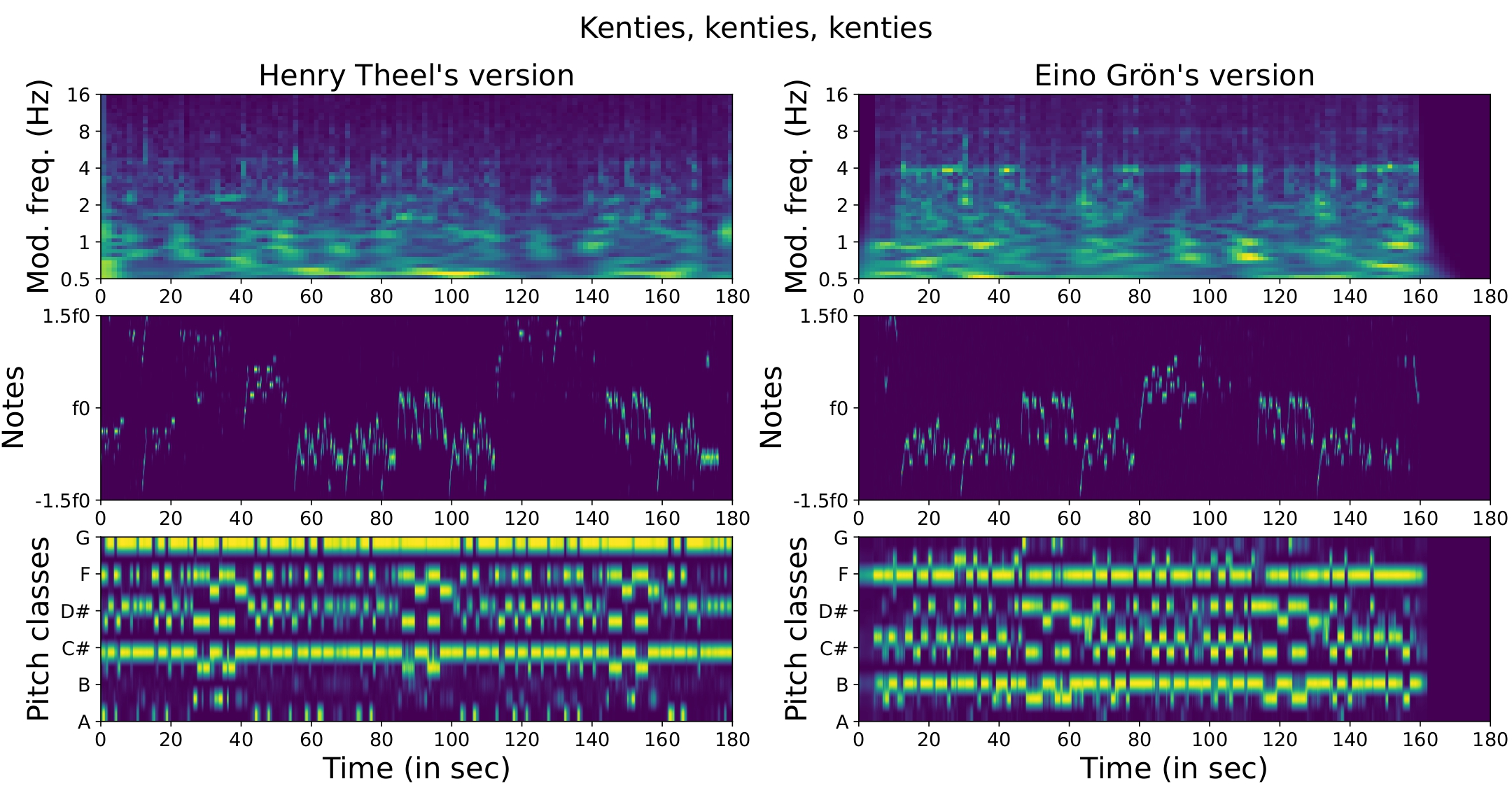
On the contrary, Rh can easily produce wrong results. This is illustrated on 2.2.1, which shows the features of two versions of “Kenties kenties kenties”. Although melody and harmony are similar, the rhythm is very different.
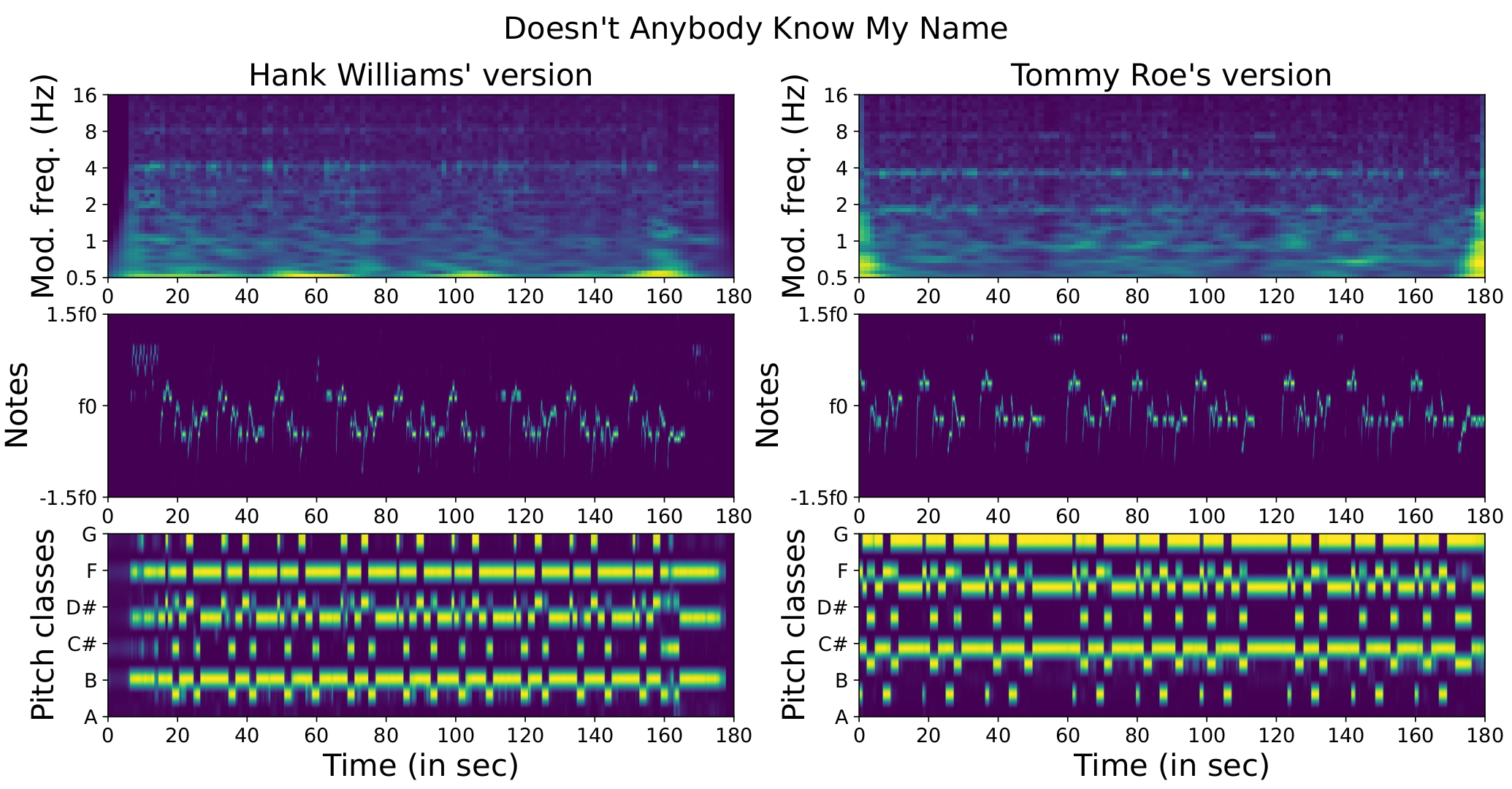
Another example is “Doesn’t Anybody Know My Name”, which does not exhibit the same rhythmic pattern in Hank Williams’ version as in Tommy Roe’s.
Some additional insights
1. Quantitative analysis
In this section, we detail the quantitative results presented in the article. We display the results for Da-Tacos-Vocals (with no instrumental songs). We also remind Da-Tacos results.
| Test set | SHS4- | Da-Tacos-Vocals | Da-Tacos | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Features | MAP | MT@10 | MR1 | MAP | MT@10 | MR1 | MAP | MT@10 | MR1 |
| Me | 0.427 | 0.822 | 1131 | 0.496 | 4.400 | 52 | 0.363 | 4.064 | 97 |
| Ha | 0.538 | 1.003 | 982 | 0.513 | 4.550 | 51 | 0.488 | 5.256 | 63 |
| Rh | 0.099 | 0.231 | 2921 | 0.075 | 0.762 | 204 | 0.055 | 0.689 | 244 |
| Ly | 0.672 | 1.190 | 968 | 0.674 | 5.931 | 59 | 0.393 | 4.596 | 199 |
| Combinations | |||||||||
| Me+Ha | 0.693 | 1.256 | 453 | 0.717 | 6.290 | 21 | 0.626 | 6.668 | 32 |
| Me+Ha+Rh | 0.688 | 1.250 | 413 | 0.650 | 5.717 | 20 | 0.557 | 5.994 | 33 |
| Me+Ha+Ly | 0.800 | 1.396 | 291 | 0.818 | 7.205 | 16 | 0.602 | 6.480 | 33 |
| Me+Ha+Rh+Ly | 0.785 | 1.378 | 286 | 0.765 | 6.714 | 14 | 0.560 | 6.054 | 33 |
Compared to the entire Da-Tacos Me, Ha and Rh features are improved (almost 15% more for the Me MAP, between 2 and 3% for the Ha and Rh MAP). But the most important improvement is the Ly feature which has its MAP increased by almost 30%. This confirms our hypothesis that the Da-Tacos results were decreased because of the numerous instrumental tracks. The add of the lyrics to the baseline no longer degrades results.
2. Distributions
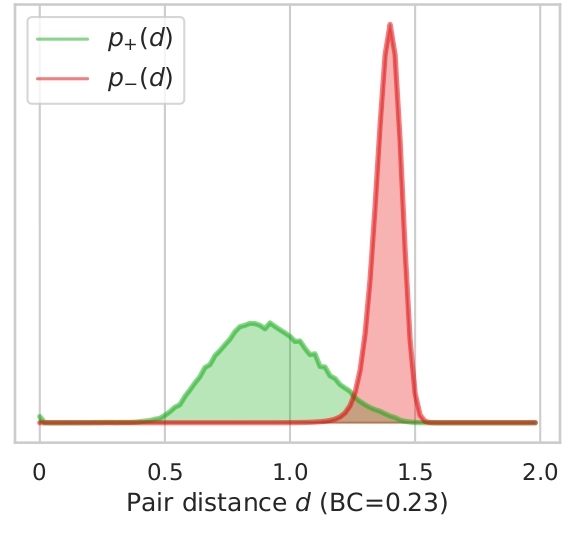
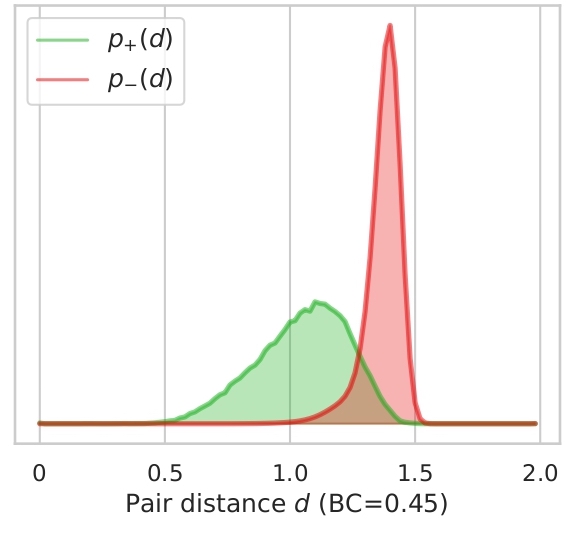
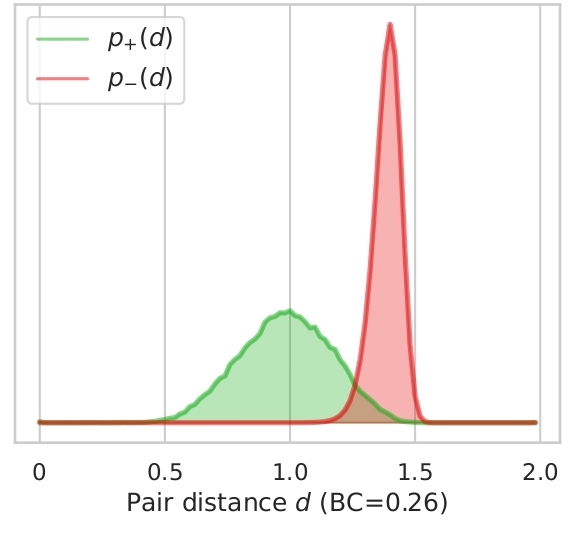
In this section we illustrate what distances, features tend to give to version pairs (positives, p+(d)) and non version pairs (negatives, p-(d)). Here we plot the distributions for both cases and the distributions for combined features for all datasets used.
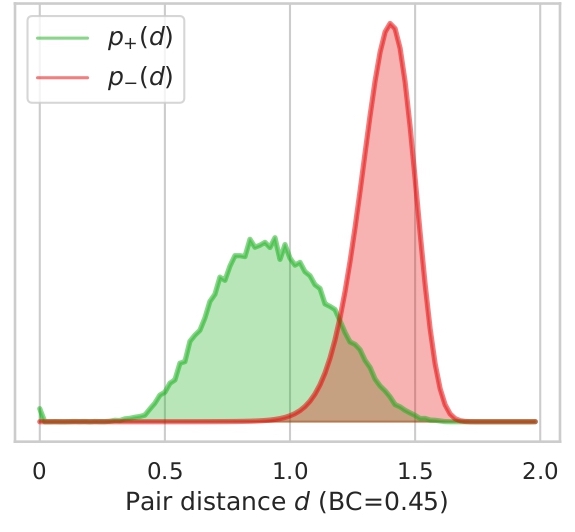
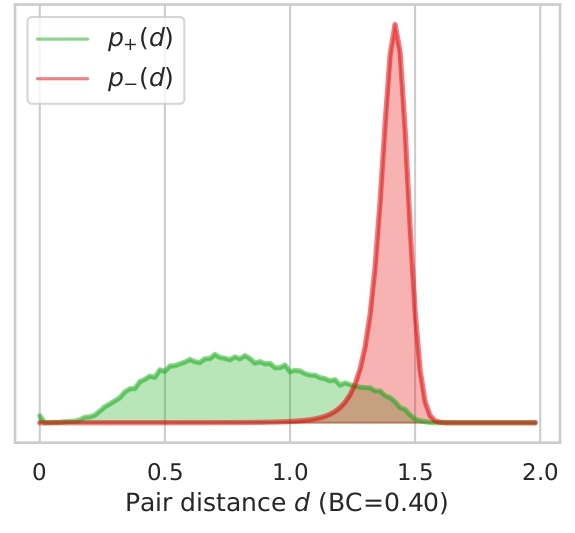
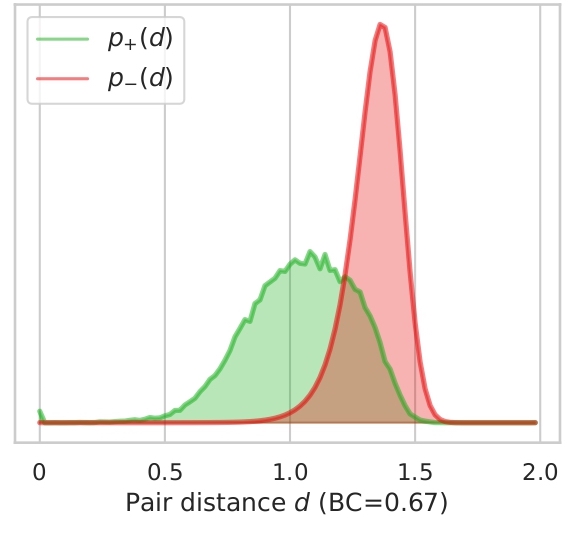
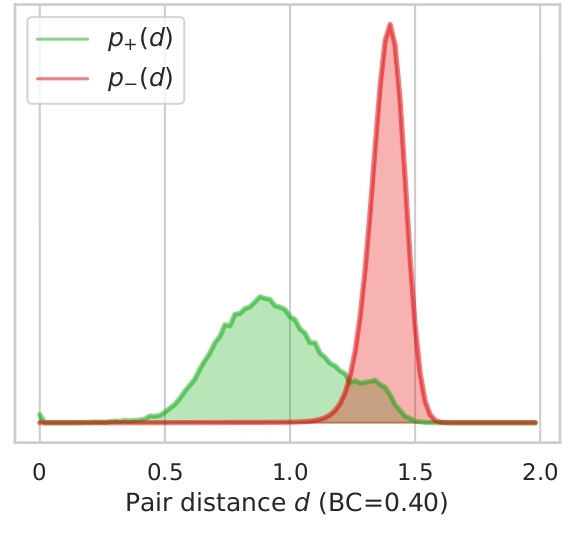
We also display the Bhattacharyya coefficient (BC) which is a measure of the overlap between two distributions.
The closer the coefficient is to zero, the more the distributions are separated and therefore the risk of false
positives or negatives is decreased. As showed in Section 4.2. in the article, the best features are Ha and Ly which
have the lowest BCs. We can also add that all features seems to be better at determining if songs are non-versions
than versions by looking at how the negative distribution is narrower. We can note on Ly distribution, a bump in the
positives with a high distance, this might be caused by some instrumental songs, song with few lyrics or versions in
different languages. This can also be supported by the Ly distributions on Da-Tacos and Da-Tacos-Vocals on figure 2.2.
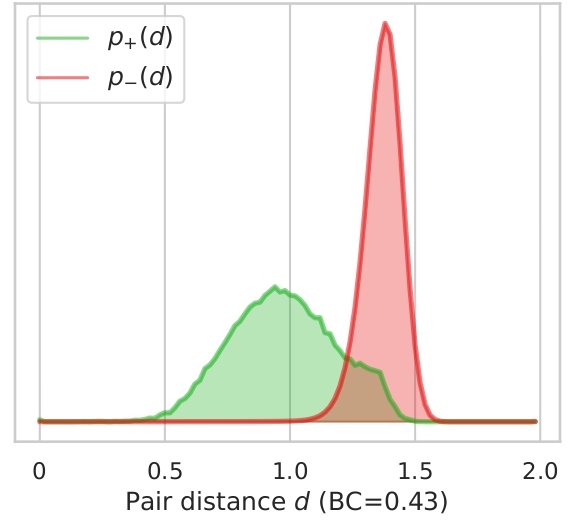
The positive distribution for Da-Tacos presents a big bump around a high distance, which is clearly attenuated in Da-Tacos-Vocals.
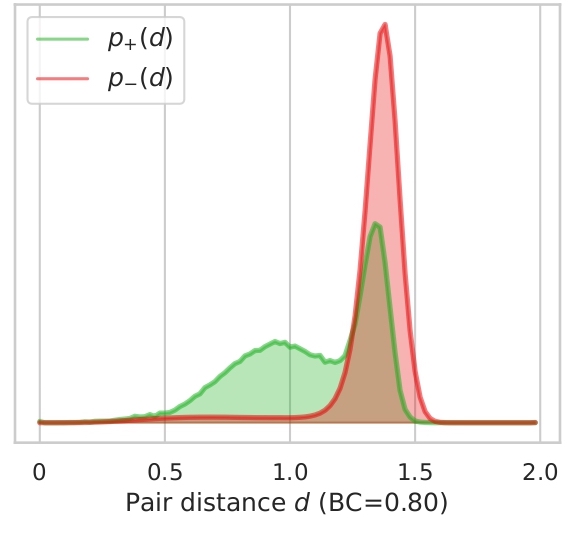
Finally we can see on Figure 2.3 how features combination can improve results. Here, the distributions are very well
spaced which avoids a big majority of false positives or negatives.
3. Clusters
In this section we display clusters as in the article, with different features and combination and on different datasets.
An interesting way to see how instrumental songs affect the system’s performances is to plot clusters for Me+Ha vs. Ly on Da-Tacos and Da-Tacos-Vocals to visualize the false negatives.
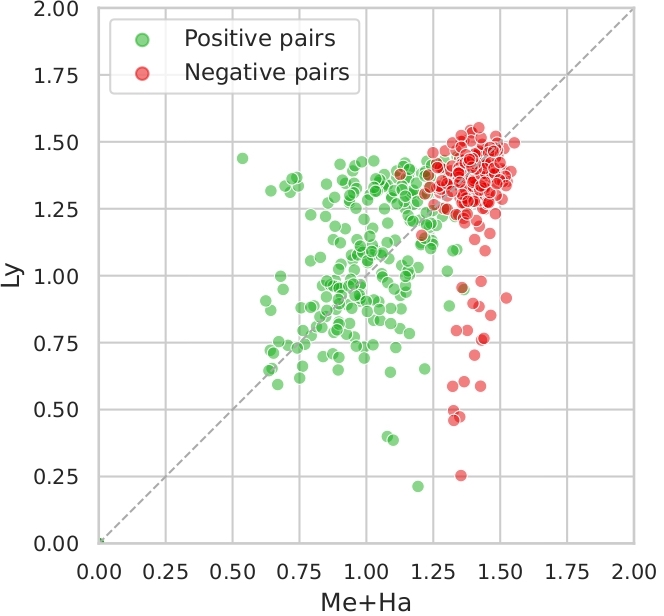
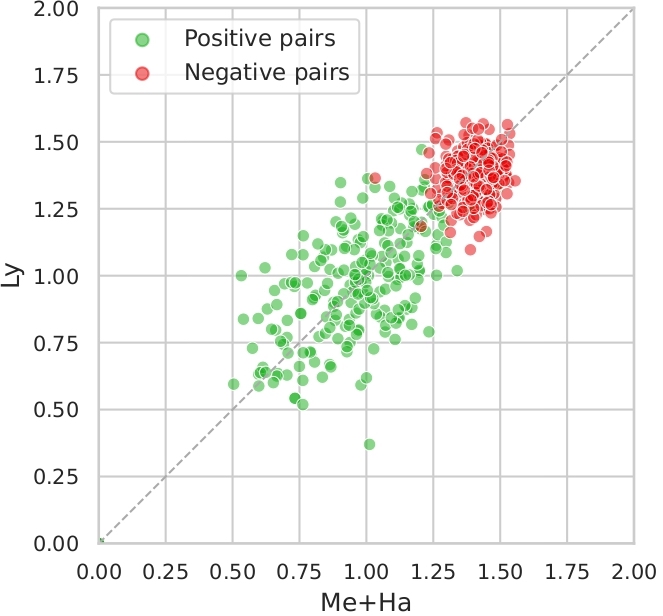
Indeed, we can see on Figure 3.1.(a) that Ly tends to give to negative pairs more smaller distances, and that this behaviour does not exist with Da-Tacos-Vocals (Figure 3.1.(b)) which suggests that those false positives were the instrumental songs which had small distances between them because of the lack of information in the lyrics.